
Цонт НИИС РАН
Вступ
Однією з основних завдань інформатики є прив'язка фрагмента інформації до того конкретного місця в більш широкому інформаційному полі, де він локалізований (фрагмента географічної карти - до свого місця на загальному плані місцевості, віршованого рядка - до свого місця в тексті і т.д.). Необхідно підкреслити, що в реальних задачах такого роду прив'язувати до свого місця фрагмент практично неминуче буває спотворений (зашумлен), що тільки ускладнює завдання. Наприклад, в довгій рядку з 0 і 1 відшукати місцезнаходження заданого фрагмента з 0 і 1, який, до того ж, може бути і зашумлен.
Загальна схема
Розроблений в ІОНТ РАН алгоритм реалізує новий варіант прив'язки фрагмента в інформаційному полі. Для реалізації пошуку в програмі невпорядкований масив інформації представляється у вигляді ієрархічної структури - дерева пошуку, на якому проводиться пошук екстремумів. Пошук проводиться за допомогою стека, який являє собою деревоподібну структуру, яка реалізує відомий алгоритм сортування Heap-Insert-Delete. (Т.Кормен і ін. Алгоритми: побудова й аналіз. М.МЦМНО., 2000), для якого число операцій вставок і витягів пропорційно логарифму від числа елементів стека. Узагальнена структурна схема рішення задачі пошуку в цілому, представлена на рис. 1.

Мал. 1.
Для початку, необхідно записати в пам'яті ЕОМ еталонне інформаційне поле, на якому буде проводиться пошук. У нашому випадку, мова йде про побудову бінарного дерева по заданих вхідних векторів. За цю процедуру відповідає блок побудови дерева. Бінарне дерево є окремим випадком від дерева і має наступні додаткові властивості:
- кожен вузол може мати трохи більше двох породжених вузлів.
- кожен вузол може бути в одному з трьох станів - "порожній", "розвилка", "термінальний".
- вихідний вузол має два породжених вузла будемо називається "розвилкою"
- породжений вузол є останнім називається "термінальним" і містить в собі ідентифікатор.
- вузол не є ні "термінальним", ні "розвилкою" називається "порожнім".
Після того як дерево сформовано, і містить всі еталонні вектора, можна приступати до пошуку. Для цього служить блок пошуку в дереві, на вхід якого подається пошуковий вектор, можливо зашумленний, а на виході знімається результат пошуку - ідентифікатор. В процесі своєї роботи даний блок, робить переміщення по дереву і формує стек, в якому запам'ятовуються і виділяються найкращі з проміжних результатів пошуку. Більш детально блоки побудови і пошуку в дереві наведені нижче.
Блок побудови дерева
Для побудови дерева, задається вектор - бінарний масив, розмір якого визначає глибину дерева. Якщо дерево ще не існує, то будується кореневої вузол. Далі проводиться послідовний перегляд компонент вектора. У разі якщо поточний елемент вектора дорівнює "1" будується правий вузол дерева щодо попереднього, в іншому випадку лівий. При досягненні кінця вектора, в кінцевому вузлі дерева встановлюється ідентифікатор записаного в нього вектора. Приклад побудови дерева наведено на рис.2. У разі, коли дерево вже існує, проводиться рух по існуючому дереву до тих пір, поки його геометрія відповідає додає вектору. Рух здійснюється аналогічно побудові; якщо поточний елемент вектора дорівнює "1" то проводиться перехід до правого дочірньому вузлу, інакше до лівого. При виявленні відмінностей між елементом вектора і подальшої геометрією дерева, будується відгалуження з поточного вузла (розвилка) і проводиться добудова дерева (рис.2б).
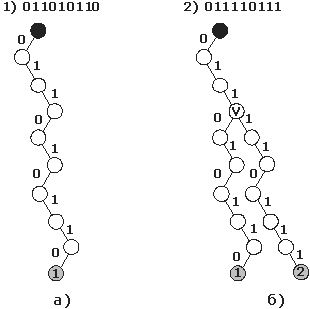
рис.2
Схема побудови дерева.
Така побудова відбувається до тих пір, поки не будуть збережені до все вектора з вхідного набору. Блок пошуку в дереві При пошуку за пред'явленим вектору, здійснюється ряд зворотних операцій; формування стека, обчислення міри близькості (М), сортування стека при додаванні в нього нового елемента, і сортування стека при вилученні з нього елемента.
Міра близькості є величиною характеризує ступінь подібності між вектором представленим для пошуку та інформацією записаної в гілках дерева.
На першому етапі в стек поміщається кореневої вузол дерева з мірою близькості рівною нулю, далі відбувається рух по дереву, при якому на кожному кроці проводиться рекуррентное обчислення значення М. Ці значення і адреси відповідних вузлів заносяться в стек. Далі проводиться сортування стека з метою упорядкування знаходяться в ньому елементів по зростанню. Потім з уже відсортованого стека витягується перший елемент містить адресу вузла дерева з максимальною мірою близькості. Починаючи з вузла дерева заданої цією адресою проводиться подальший пошук, до тих пір, поки не буде досягнутий або кінець вектора, або одна з кінцевих вершин. Вищесказане можна представити у вигляді алгоритму:
1. Прийняти М1 = 0, M2 = 0
2. Прийняти вузол У1 і У2 рівними кореневого вузла дерева
3. Помістити в стек вузли У1, У2, з заходами близькості М1 і М2.
4. Якщо один з вузлів термінальний, то йти до п. 13.
5. Провести читання кореневого вузла стека 'У
6. Знайти цей вузол в дереві пошуку 7. Якщо вузол порожній то, йти до п. 9.
8. Якщо вузол - розвилка то, йти до п. 11.
9. Обчислити М1 для породженого вузла У1 від У.
10. Перейти до п.12.
11. Обчислити М1 і М2 для породжених вузлів У1 і У2 від У.
12. Перейти до п. 3.
13. Висновок результату.
14. Кінець
блок стека
Як видно з попереднього опису, на кожному кроці своєї роботи блок пошуку в дереві звертається до стека і виробляє з ним операції читання і запису. У стеці, при кожному зверненні до нього, відбувається сортування його вмісту. Кінцевою метою це сортування є приміщення в кореневий вузол стека вузла має максимальне значення міри близькості.
Додавання нового елемента в стек проводиться таким чином:
1. Якщо число вузлів в дереві стека дорівнює 0, то створюється коренева вершина і в неї записується вміст додається елемента.
2. В іншому випадку обчислюється номер вузла, кількість нащадків
3. Викликається процедура сортування стека.
Сортування проводиться класичним алгоритмом Heap-Insert-Delete:
1. У дереві стека вибираються два вузла: останній доданий і його вихідний.
2. Порівнюються міри близькості записані в цих вузлах. У разі, якщо міра породженого вузла більше заходи вихідного, вузли міняються місцями.
3. Далі процес відбувається циклічно, піднімаючи останній доданий вузол вгору по гілці дерева до тих пір поки, він не займе своє місце.
В результаті роботи цих алгоритмів, в кореневій вершині стека буде знаходитися вузол, що містить в собі адресу вузла дерева-пошуку з максимальною мірою близькістю.
Після його вилучення, потрібно знову впорядкувати стек, відшкодувавши відсутність кореневої вершини.
1. На місце кореневого вузла поміщається останній вузол дерева стека.
2. Проводиться порівняння заходів близькості, що містяться в трьох вузлах: поточному і двох породжених від нього. Для початку вибирається максимальне значення міри близькості серед двох породжених вузлів, а потім це значення порівнюється з мірою близькості в поточному вузлі.
3. Міняються місцями поточний вузол і породжений від нього з максимальною мірою близькості.
4. Поточний вузол переміщається вниз по дереву до тих пір, поки не займе своє місце в дереві стека.
В результаті роботи цих трьох алгоритмів відбувається сортування стека, яка дозволяє вибирати вузол з максимальним значенням міри близькості, що знаходиться в ній.
Для демонстрації алгоритмів побудови і пошуку, описаних вище, були написані демонстраційні програми, опис яких наводиться нижче.
експеримент
Проводилась кілька серій експериментів над безліччю бінарних дерев різної довжини. Для пошуку задавалися послідовності різної довжини і різного ступеня зашумленности. Кожна серія включала в себе 1000 експериментів. Спочатку була знята характеристика залежності відсотка помилки (величина зворотна міру близькості) від відсотка зашумленности для різних довжин дерев і для різних довжин послідовностей пропонованих для пошуку. Потім були отримані залежності відсотка помилки від відсотка зашумленности, при постійній глибині дерева і довжини пошукової послідовності, і змінному числі векторів записаних в дерево.
Далі проводилася серія експериментів для зняття залежності відсотка помилки від числа векторів записаних в дерево постійної довжини, при різного ступеня зашумлення пошукової послідовності постійної довжини.
І нарешті, залежність числа операцій від числа векторів записаних в дереві постійної довжини, при різного ступеня зашумлення пошукової послідовності постійної довжини. На підставі знятих даних були побудовані графіки, наведені на рис. 3.

Мал. 3. Залежність помилки від шуму. L - глибина дерева. H - довжина пошукового вектора.

Мал. 4. Залежність помилки від шуму. Глибина дерева і довжина пошукового вектора постійні і рівні. М - число векторів записаних в дерево.

Мал. 5. Залежність помилки від кількості векторів записаних в дерево постійної глибини при різному рівні шуму.
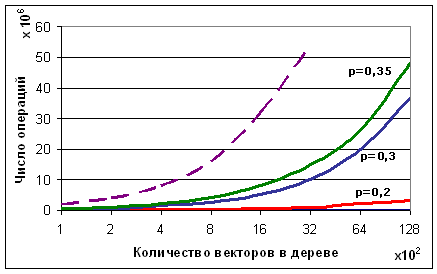
Мал. 6. Залежність числа операцій при пошуку від кількості записаних в дерево векторів для різних рівнів шуму. Глибина дерева і довжина вектора постійні. Пунктирною лінією на графіку показана залежність при простому переборі без використання бінарного дерева.
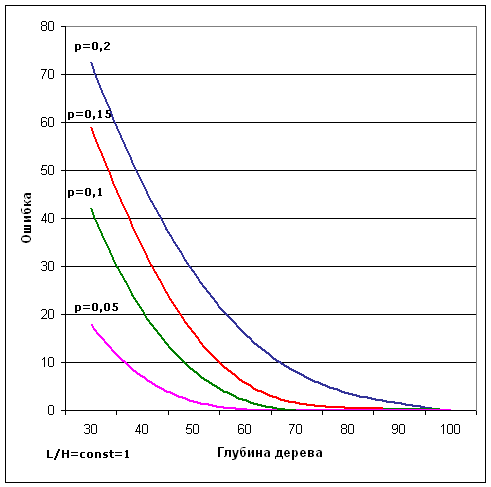
Мал. 7. Залежність помилки від глибини дерева при різних рівнях шуму.
З отриманих кривих можна зробити висновок про те, що даний метод показує досить непогані результати за всіма характеристиками при невеликій кількості векторів записаних в дерево (~ 100-200). При збільшенні цього числа або зашумленности вхідної послідовності, різко зростає відсоток помилки і кількість операцій необхідне для твору пошуку. Це пов'язано з тим, що при проходженні дерева в процесі пошуку, в цих умовах, число прохідних вузлів різко збільшується і наближається до половини всіх вузлів, на яких побудовано дерево, отже, на кожному такті витрачається значна машинний час для його сортування.
З експериментів була знайдена помилка розпізнавання Ver, значення якої можна виразити формулою

Найбільший інтерес для практичного використання представляє та область змінних (область допустимості), в якій помилка розпізнавання Ver << 1, що досягається при z << 1. При цьому Ver ≈ z.
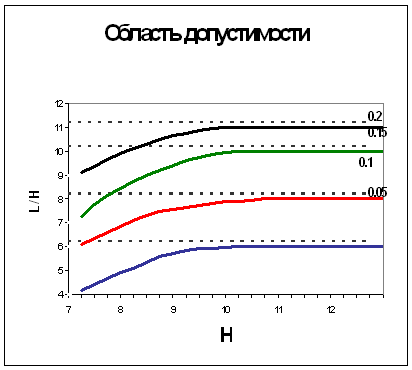
Рис.8 Область допустимих значень L / H при різних рівнях шуму.
На рис.8 наведені криві, побудовані для різних рівнів спотворень (p = 0,05; 0,10; 0,15; 0,20). Суцільна лінія розмежовує області застосування алгоітма пошуку: для точок, розташованих нижче кривої (малі значення L / H) число операцій неприпустимо велика, тобто наростає експоненціально з ростом числа векторів М, а помилка розпізнавання більше 0,01; в області вище кривої алгоритм успішно працює і його швидкодія наближається до теоретичної межі, а помилка розпізнавання менше 0,01. Для розмежування областей допустимості і неприпустимість замість кривих зручніше використовувати їх асимптоти - пунктирні лінії на рисунку 8.
Наприклад, при p <0,05 областю допустимості є значення L / H> 6, тобто для успішної роботи алгоритму пошуку слід використовувати дерево з глибиною L> 6log2M.
Під областю допустимості ми маємо на увазі область значень параметрів, при яких імовірність помилки Vош нехтує мала, а число операцій зростає лінійно з ростом глибини дерева L, тобто:

де N0 - число операцій у відсутності шумів, а експериментально встановлена величина Cp мало відрізняється від одиниці:

Величина k в цьому виразі лінійно залежить від L, порядку k ~ C1 + C2 (L + H) lnH ~ 100, де C1 і C2 - несуттєві константи (див. Нижче). Перший доданок відображає рух по дереву пошуку. Другий доданок в цьому виразі пов'язано з операціями читання і запису в стек. Узагальнюючи аналіз області допустимості, слід рекомендувати наступні параметри, при яких алгоритм пошуку працює успішно: відносно малий рівень шумів p? 0,2 і досить велика глибина дерева L> 10 log2M.
Опис демонстраційної програми пошуку зашумленной бінарної послідовності в дереві.
Після запуску програми на виконання (demo2.exe) буде проведена завантаження бінарного тексту в дерево (рис.9)

Мал. 9.
Потім, перед користувачем з'явиться форма зображена на рис.10, на якій розташоване поле завантаженого в дерево тексту, і є рядок для введення пошукового рядка - "Рядок пошуку".
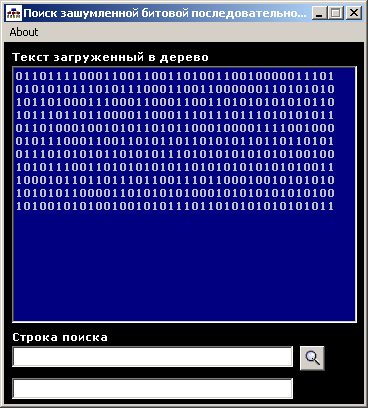
Мал. 10.
Після введення в неї бінарної послідовності, послідовності, необхідно натиснути кнопку пошуку (  ). Результат видається програмою може бути різним у залежності від того чи зустрічається введена послідовність в сформованому дереві цілком, чи ні. У першому випадку буде видане відповідне повідомлення і виділені всі відповідні області в тексті (рис. 11). У другому буде виведено повідомлення про те що точних відповідностей, не знайдено, і проведений пошук найбільш близьких входжень по дереву (рис. 12).
). Результат видається програмою може бути різним у залежності від того чи зустрічається введена послідовність в сформованому дереві цілком, чи ні. У першому випадку буде видане відповідне повідомлення і виділені всі відповідні області в тексті (рис. 11). У другому буде виведено повідомлення про те що точних відповідностей, не знайдено, і проведений пошук найбільш близьких входжень по дереву (рис. 12).


Мал. 11
Мал. 12
З метою недопущення некоректного введення, перевіряється вхідна послідовність на наявність сторонніх символів. Після здійснення пошуку, до подачі нової пошукового рядка, кнопка пошуку відключена.
 Завантажити демонстраційну програму (274 кБ)
Завантажити демонстраційну програму (274 кБ)
Демонстраційна програма прив'язки на місцевості.
Для демонстрації алгоритму швидкого пошуку по заданій послідовності в бінарному дереві, була написана програма імітує політ об'єкта в просторі. При запуску файлу UFO.exe після деякої затримки, під час якої відбувається формування карти місцевості, перед користувачем з'являється вікно зображене на рис. 13.

Мал. 13.
Червона крива на малюнку, являє собою траєкторію, якою повинен дотримуватися об'єкт. Виділені області зоряного неба є ділянками в яких об'єкт може визначати свої координати, виробляючи пошук по бінарним дереву. Поза цими областей об'єкт рухається инерциально, повторюючи закладену в пам'яті траєкторію руху. В цьому випадку при впливі сил, що обурюють - "Вітру" відбувається його відхилення від заданого курсу (рис. 14).

Мал. 14.
У нижній частині вікна програми розташований ряд кнопок і перемикачів перемикають режими її роботи. Зокрема, можна ввімкнути або вимкнути вплив "вітру" за допомогою відповідного перемикача, відображати реальну траєкторію руху об'єкта, спостерігати графік відхилення від заданого курсу (рис. 15).

Мал. 15.
Крім того, є можливість переключитися з працюючого за замовчуванням режиму инерциального руху об'єкта в режим прив'язки до місцевості і назад, за допомогою відповідних кнопок. У режимі прив'язки до місцевості, програма формує бінарний вектор місцевості, в яку потрапив об'єкт і здійснює пошук цього вектора в дереві. В результаті визначаються координати об'єкта щодо поточної області прив'язки і проводиться коригування курсу (рис. 16а, 16б);

Мал. 16а. Режим прив'язки до місцевості включений з самого початку руху
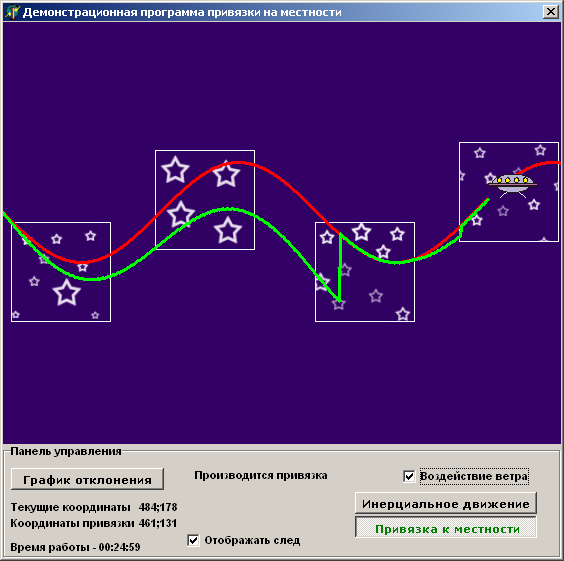
Мал. 16б.Режім прив'язки включений після вже значного відхилення об'єкта.
Завантажити демонстраційну програму (363 кБ)
література
- Кнут Д., Мистецтво програмування для ЕОМ. Сортування і пошук, т.3, М., Мир, 1978.
- Кормен Т. та ін., Алгоритми: побудова й аналіз, М., МЦМНО, 2000.